I mentioned this before, but to me, high-quality code has 3 attributes: it’s easy to understand, easy to change, and correct. I always start with trying to make any piece of code the easiest to understand. If you make it easy to understand, even if it’s not easy to change or correct yet, you are in a much better position than otherwise. Whenever I’m mentoring I always explain it like this: if you can understand the “what” you can change the “how”.
So, making the “what” explicit, that’s the challenge.
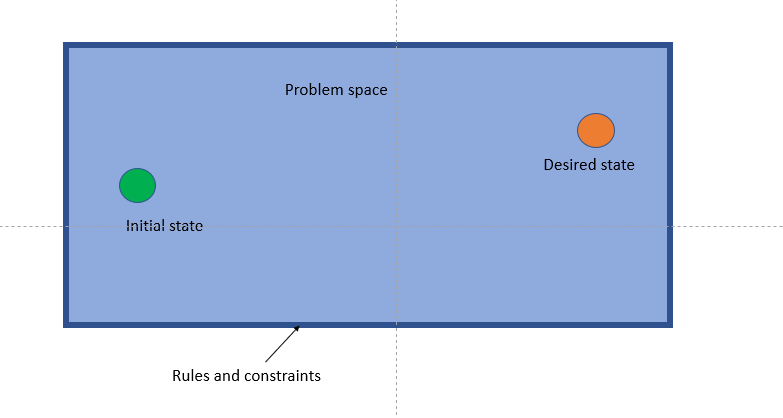
The socio-technical space
There’s this idea in the DDD circles called socio-technical space. The way I like to think of it is like a continuum that has technical issues/solutions on one side and social issues/solutions on the other.
When you start looking at social issues, the concepts and their interactions provide you with a nice framework where you can reason about the problem. Often, your design will take after these concepts as the building pieces for your solution. That means that if you are working on a system for a banking domain, you likely will have objects like accounts, money, and credit.
But what when you are solving a highly technical problem where the concepts are too vague, abstract, or low level? Well, you can try defining your own concepts to reason the problem and to explain your solution. Or you could use a metaphor.
A technical challenge for you
Exercism.io is a platform to practice solving problems in a programming language. I recommend it to any developer who takes pride in his/her craft. So I was solving the Spiral Matrix problem (login/sign up to access the problem). Before you continue reading I challenge you to solve it. Go on, I’ll wait for you.
So the problem states that given a size you have to create a Matrix[size, size] and you have to fill it with numbers starting from 1 up to the last element. Suppose you have a Matrix[5, 5] then you would have to fill all the slots with numbers 1 to 25. The tricky part is that you have to follow an inward spiral pattern. Are you interested now? try solving it!
Metaphors to the rescue!
The first time I heard about metaphors in the software development realm, was in relation to XP. The idea is simple: use a metaphor to drive the system design. Kent Beck used this on an overall system design level (architecture). But this time I’ll apply it on a smaller scale: the Spiral Matrix solution.
Each XP software project is guided by a single overarching metaphor… The metaphor
-Kent Beck, Extreme Programming Explained
just helps everyone on the project understand the basic elements and their relationships.
Patterns, patterns everywhere!
There are many ways to solve the Spiral Matrix problem. The most obvious solution is to sense the surrounding cells as you move. However, as I was looking at the numbers, I found a pattern in them. Turns out that you can calculate the turning points.

Here I marked all the turning points for a 3×3 matrix. If you lay out the numbers the pattern makes itself visible.

So starting from the right to left, you’ll notice that the distance between the 2 turning points is 1 (where distance is how many spots you’ll have to traverse before finding the next turning point). After the 2 turning points the distance increases by 1. And the sequence goes on. Every 2 turning points the distance increases by 1 until it reaches size-1. I’ll leave it to you to come up with an algorithm to take advantage of this. By the way, the number of turning points is equal to (size * 2) – 2.
Enough talk, show me the code!
So I wanted to make this pattern as obvious as I could, but after the first implementation, it was everything but obvious. After looking closely I noticed there were several things happening at the same time: keeping track of the corresponding number, moving on the grid, and knowing when to turn. So I decided to create objects to handle those responsibilities… but how should I call them?
Sure, you can call your objects however you want, but I wanted to make everything as clear as possible. Easy to understand, remember? So one of the responsibilities was to “navigate” the matrix. This led me to decide on a map. A map helps you navigate right? who could use a map? An Explorer right? after some iterations I ended with something like:
public static int[,] GetMatrix(int size)
{
var terrain = new int[size,size];
var compass = new Compass(size);
new Explorer().ExploreTerrain(terrain, compass);
return terrain;
}
So imagine you were tasked with starting the numeration at 3 instead of 1. You come and find this code. You’ll probably be puzzled, but the objects make sense to you. Because you understand the relationship between an explorer and the compass. You understand how the compass is used by the explorer. And knowing that, it makes sense to you that the explorer would use a compass to explore a terrain. Actually, it would be weird if he didn’t. But all of this happens in the back of your mind in a fraction of a second, without you really noticing it. So you go and check the ExploreTerrain method.
public void ExploreTerrain(int[,] terrain, Compass compass)
{
while (_stepsTaken <= terrain.Length)
{
mapCurrentPosition(terrain);
adjustDirection(compass);
advance();
}
}
Again, this code is taking advantage of you existing knowledge on the matter of exploration. Wait what is this mapCurrentPosition doing? I think I know, but let’s confirm it.
void mapCurrentPosition(int[,] terrain) =>
terrain[_currentPosition.Y, _currentPosition.X] = _stepsTaken;
oh! so it’s putting a number in there… given what we know, this should be the corresponding number… so that is referenced as _stepsTaken! ok, let’s go back. Wait how is adjustDirection accomplished?
void adjustDirection(Compass compass)
{
if(compass.IsTurningPoint(_stepsTaken))
_currentPosition.TurnRight();
}
So if the compass says that I need to turn at the current step, I turn right (notice how this didn’t puzzle you. Because using a compass to figure out if you need to turn around is something you understand, maybe even experienced before). Maybe we should rename that _stepsTaken variable to _currentStep? let’s go back and figure out what the advance method does.
void advance()
{
_currentPosition.Forward();
_stepsTaken++;
}
Well, yeah, as expected. Wonder, how does the _currentPosition move forward? (notice we are questioning the “how” not the “what”. We understand what “moving forward” means when exploring). But hold on! where is that _stepsTaken initialized?
class Explorer
{
int _stepsTaken = 1;
...
}
Bingo! let’s initialize this variable to 3 instead of 1 and presto!
class Explorer
{
int _stepsTaken = 3;
...
}
I think you got the idea. If you want to check the details you can find the whole code here.
Closing thoughts
Hopefully at this point the advantages of using a metaphor have become evident (especially in an object oriented system).
Another benefit of using a metaphor is communication. Good metaphors are based on everyday experiences that a lot of people can relate to. This will allow you to convey ideas about the system design/architecture to non-technical people, which becomes increasingly important in agile settings, where the customer is part of the team.
I hope this picks your curiosity about using metaphors in the code. We already do it to explain our ideas in other settings, so why not use it in our code too? I challenge you to do it!