Category / Uncategorized
Leaky abstractions and how to deal with them
Leaky abstractions is a term given to a faulty model, that is a model that fails to express some domain concepts. I found this to be a natural step on the process of creating a rich domain model. The problem comes when we stop refining the model, ending up with an incomplete work.
The school example
John was tasked to create a system to replace a legacy school administration system. His initial approach was to review the old systems database to extract the underlying entities. If not the code, at least he could reuse the abstractions. So, he ended up with the following abstractions:

Then he proceeded to work with the first use case/ user story: student registration. When finished, it looked something like:

“So far so good”- John thought – and he went to work on another use case. However, as he progressed he notice that the student object was over bloated: it contained info no only related to the student performance but also financial and historical data. Can you guess why?
Hunting a missing abstraction
Turns out that since every career has its own set of requirements, the student object had to accommodate all the data needed by every career prospect evaluator object.
The problem with John’s model it’s that is missing an abstraction. Thus, he is reusing another abstraction in place. Unfortunately, that’s a COMMON mistake. And one with a HUGE impact. The missing part here is the application the student submits. Let’s introduce this into the model.

This frees the student object to represent an actual student and nothing more. Now we can have the AccountingEvaluator evaluate an AccountingApplication.
By doing this we have:
- Reduced coupling since the student object is not dependent on the requirements of the program evaluators.
- Made the code SRP compliant, hence easier to maintain.
Keeping it simple
By this point some may be thinking that we increased the cyclomatic complexity since now we have to figure out the right evaluator for each application. Something like this:
Public void Submit (ProgramApplication app){
var type = app.ToString();
switch(type){
…Code to select the right evaluator…
}
}
But this can easily be fixed by putting the responsibility into the application objects themselves:
public interface ProgramApplication{
bool IsApproved();
}
public class EngineeringApplication: ProgramApplication{
decimal _mathScore;
public EngineeringApplication(mathScore){
_mathScore = mathScore;
}
public bool IsApproved(){ return _mathScore > 90}
}
public class AccountingApplication: ProgramApplication{
decimal _mathScore;
public AccountingApplication(mathScore){
_mathScore = mathScore;
}
public bool IsApproved(){ return _mathScore > 80}
}
//call on the client side
Public void Submit (ProgramApplication app){
if(app.IsApproved()) ...
}
This is good design as it encapsulates the application evaluation details.
Closing thoughts
John’s is a typical scenario of leaking abstractions. The problem here is that he believed the domain model of the legacy system to be complete. This is a common mistake when starting a new project (either green or migrating any obsolete piece of code). We must remember that the moment we know less about the business is at the beginning. It’s naïve to expect the domain model to be complete on this stage. I learned at school that aversion to change is a human trait, but don’t hung up to faulty model. If it’s too complex, we’re doing it wrong.
Keep refining your model and have fun!
How to handle dependent observable calls in an async call in Angular 2/4
Recently I’ve been working with Angular 2/4. One day I came across with something like this:
public getCustomersOnArea(zip:string):Observable<Customer>{..}
The problem was that we had to make 2 calls to get the data. Even more one call depended on the data fetched from the other. How to solve this? One way it’s to encapsulate the 2 calls into a third one and return that to be subscribed.
public getCustomersOn(zip:string):Observable<Customer>{
return new Observable<Customer>(subscriber => {
this.http.post(zip)
.subscribe(res => {
this.http.post(res)
.subscribe(r => {
subscriber.next(r);
},
e=> subscriber.error(e),
()=> subscriber.complete());
});
}
And that’s it. Do you know another way? Leave it in the comments section
Are you a bad programmer?
I believe that knowing where are you lacking will make you a better programmer. At least a more aware programmer. However, having someone to point out what we are doing wrong is something not everyone can handle. That’s why self evaluations are so valuable. But you need some sort of standard in order to do so. I found an old (but still valid) post interesting enough to share. I gained some insights about the stuff that I need to improve from it. You can find it here. Do the exercise and let me know how it goes.
DDD vs Clean architecture: hosting the business logic
In my previous post I mentioned that there are 2 types of code: business and plumbing. I pointed out that business code is not meant to be reusable in as much as plumbing code. The reason is simple: business code is business specific, which means is tailored to a specific business way of doing things. But even more, this code can be sub domain specific; i.e. think of a pencil factory: it has several departments such as Marketing and Engineering. To them, the word “product” can mean something very different.
Are business objects sub domain exclusive?
So the question here is: how do we dealt with scenarios where the same concept has a different meaning to different people in different departments? Let’s see how 2 fabulous architectures approach this problem: Domain Driven Design by Eric Evans and Clear Architecture by Robert C. Martin.
Make the context explicit
So Eric Evans makes a clear declaration on the matter: objects are context bound. By context we mean sub domain/department. He makes the context explicit so the behavior of the objects it’s defined by the context they live in. Going back to our first example we would declare 2 contexts: one for marketing and one for engineering. This could be easily represented as namespaces or packages. So now we can have a product object in the Engineering context which can determine how many pieces of itself can be build with the raw materials in stock. Something like:
var product = new Engineering.Product(); int qty = product.BuildWith(currentStock);
While the product object on the marketing context may look something like:
var product = new Marketing.Product(); decimal price = product.PriceFor(aGoldCustomer);
DDD is not afraid of having 2 different classes with the same name in their own context each. Truth be told, trying to have a single object to represent the different concepts in each domain is the result of a wrong abstraction process.
Make the objects gluten free
The alternative proposed by Clean Architecture is to create business objects with the most basic behavior, which allows for them to be reused in different contexts.These business objects are then used by use case objects. The context here doesn’t need to be explicitly defined. It can be implicit in the use case object. So while the business objects feature enterprise wide behavior, the use cases objects contain the application specific behavior, that is, the rules used by the context on which the use case is defined.
CreateNewCustomerOrder{
...
Execute(){
var product = new Product();
decimal price = product.GetCost() *1.5;
...
}
}
CreateNewProductionOrder{
...
Execute(){
var product = new Product();
decimal totalOperationCost = product.GetCost() * qty;
...
}
}
The answer lies in the abstraction
So as you can see both DDD and Clean Architecture are very similar. They both put emphasis on the business objects. Both decouple the domain from any external dependency. Both have objects to represent use cases and accomplish their mission coordinating the business objects. The difference lies in that while DDD puts all the business rules in the business objects in as much as possible using a level of abstraction closer to the context, the clean architecture uses higher level of abstraction on the business objects and a level of abstraction closer to the context on the use case objects. In the end all comes down to the degree of abstraction that you choose your domain to be on. So which style do you found most attractive?
Let me know your thoughts.
Generic code vs flexible code
It was on one of those rare occasions: We we’re starting a new system from scratch. The excitement was palpable. As some devs(myself included) started using TDD, some other where busy trying to figure out an architecture to hold everything in place. We decide to hold some code reviews to keep everyone on the loop. And that’s how the clash happened. I was astonished when another developer suggested that our code wasn’t generic and so it was unable to cope with the changing requirements. It was true that our code wasn’t overly generic. But it was flexible.
The quest for adaptability
Adaptability is a desired trait in software because it helps us cope with changes without having to rewrite everything from scratch. Typically you deal with this by 1) making the software so generic that there’s no need to change it, just configure it and you are done, or 2) by making the code easy to change.
![]()
The difference between the 2 strives on the abstraction level.
Generic code
Generic code embraces the idea that you can have one code base to rule them all. All you need to do is make it highly reusable. The key is to work at a high level of abstraction. Doing this has the benefit that a lot of customers can use the system as long as they don’t have specific requirements. Let’s consider an Agenda application. You could use an AgendaItem to represent anything from an appointment with your boss to a reminder to pick the laundry before sunday. So let’s say you want to introduce project management. How would you tackle that? You could modify the AgendaItem to include another AgendaItems. So now every AgendaItem can represent an appointment, a reminder or a project. Can you see what the problem is? By working at a higher level of abstraction you can represent a lot of the stuff that can be put on an Agenda but this will become increasingly harder to maintain as changes required by the different concepts it represents will force the AgendaItem object to grow complex over time. Even so you’ll be fine if you don’t need to manage projects or if you create a list somewhere else to relate certain AgendaItems to a project.
Flexible Code
On the other hand of the adaptability spectrum, we have flexible code. Flexible code in this context means code that is easy to change to accommodate new features.
The big question
So let’s say you are starting a new project, should you go for a Generic or Flexible code base? Well… it depends. Are you working on a Line Of Business application? Are you making a framework for others to use?
On a Line Of Business application
There’s 2 kinds of code: business specific and what I call plumbing code.
Business specific code is the code we are paid to write. It adds value to the business. It contains it’s particular rules. The business doesn’t care about the database choice, the technology stack or the OS on which the application runs. And the code that contains their rules and logic shouldn’t either. Don’t be afraid to model your objects to reflect your specific business even if it’s a bit different from the rest of the industry. This code is no meant to be reused outside your application.
Plumbing code refer to all the code that is common in almost every application: things like mail sender objects, ORM, frameworks… that sort of stuff. Void of logic, highly reusable.
A LOB application contains both kinds of code, but the plumbing code must serve the needs of the business code.
On an application framework
Think of code like Angular, the javascript framework. That’s stuff designed to be used by other developers to create web applications. As such it’s void of any application specific code which makes it highly reusable. It also uses highly abstracts concepts, such as that of a component which can represent pretty much anything on the screen: from a link to a complete page.
The trap of reusability
The problem arise when we want to reuse everything on a LOB application; that’s a crazy idea! The moment you decide to reuse the business specific code, you force yourself to start thinking on a higher level of abstraction thus leading to a very generic code and as we have already seen, that makes it hard to implement specific business rules. Do not fall into the trap that everything has to be reusable. Odds are that the next project you work on the same domain, you won’t be able to reuse your domain objects due to the specific client/business rules. When it comes to LOB applications, is the knowledge and not the business specific code what’s reusable.
Closing thoughts
If you are working on a LOB application, go for a generic style on the plumbing code, but take a flexible approach for the business specific code, that is do not go too abstract on this. If you are working on an Restaurant application, don’t create a “dish” object with an ingredients collection that represents everything you can serve there. Instead make explicit representations for each dish. Is that an Italian restaurant? Chinese? Thai? Then make a “spaghetti” object, or a “dumpling” object. They all may inherit from a “dish” object and contain an ingredients collection but they are not generic dishes. They are the restaurant dishes, the business products, and you want to identify them as that. Don’t be afraid to be specific.
This all may sound like common sense and it is! It’s just that in my experience, common sense is not always common practice.
Let me know your thoughts.
The calculator challenge: resolved
A couple of weeks ago, I shared an exercise I used to evaluate OO design skills on recruiting interviews. I got some interesting feedback from different people out there. Today I want to share an answer. As someone pointed out, this is a very simple problem, but even so, I could find no one to solve this. Not even one. In my experience, the moment the interview went on another direction than a CRUD exercise the developer find himself lost. So let’s review the problem statement:
Design a program that given a string such as “(1+2)/3*4” returns the correct result.
Finding the abstractions
So we need an object that evaluates an expression and returns a numeric value. Straightforward.
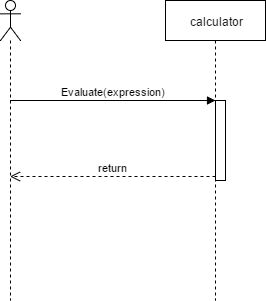
However, having an object that evaluates every single type of operation present in the expression is a violation of the single responsibility principle. The solution? Divide and conquer. Let’s create an object for each operation.

Now, all the calculator must do is to pass the expression to every operation object. Even when the message it’s called Evaluate, the return value from each operation object should be the expression with the values in place so that it can be passed to the next operation object. To extend the calculator capabilities all that’s needed is to add another operation object. This can easily be accomplished using an interface implemented by all the operation objects.

Focusing on the what, not how
I want to bring your attention to the fact that so far we haven’t discussed how this objects are going to evaluate the relevant bits of the expression. We don’t even have the data types on the messages (is expression a string or an object?) To me this is the hallmark of an experienced OO developer: the ability to focus on the big picture and ignore the little details until needed. This is called abstraction. Traditionally we are trained to start thinking on an algorithmic way, thinking of every minute detail. It takes some time and effort to start focusing on the what and leave the how to later. Going this way, we can use another technique to design the objects internals (the how, the implementation details) such as TDD. For the record, I’d probably use a regex to match the arithmetic sign, extract the values, execute the operation and replace the value back into the expression.
The next challenge
So, if you ever were on an interview with me, this is the answer that you probably almost found. Anyway, I have another challenge here: Can you identify the design patterns used in this solution? Which patterns would you use to improve it?
The phoenix project review
I just finished reading The Phoenix Project, a book in the style of Eliyahu M. Goldratt’s The Goal. I’ll try to cover the main ideas without going into too much detail. If there’s interest I can dig more into a specific theme or idea.
The Premise
Probably the main idea is that the software construction process is alike to a manufacturing plant line of production. If you have never been into the manufacturing process there are some concepts that you need to understand before going further.
Bill of materials
The Bill of Materials (or BOM) is a list that contains all the components needed to create a product, all the way down to the raw materials. An example could look something like:
- Product X
- Component 1
- Sub Component 1
- Sub Component 2
- Component 3
- Component 2
- Sub Component 3
- Raw Material 1
- Raw Material 2
- Sub Component 3
- Component 3
- Raw Material 3
- Sub Component 4
- …
- Component 1
The BOM also includes the amount of each component or material needed.
Work Center
The work center as it name implies is a specific place where a specific activity takes place. Ie. in an automobile manufacturing plant, there could be a work center where the doors are attached, another where the motor is inserted in the vehicle and another one where it’s painted. In the phoenix project there are 4 elements in any work center: the machine, the man, the method and the measures. A work center also has a wait time: the time it takes to start working on an assigned task. The more tasks are pending to be executed by a work center, the more wait time it’ll take to start working in the latest assigned task. This is represented by the following formula:
Wait Time = % busy / % idle
Bill of Resources
The Bill of Resources = BOM + Work centers + routing, where routing specifies which work centers are needed to finish a product and in which order. Basically it list all the steps needed to complete a product.
The software feature release as a production line
According to the book, there are some work centers where certain activities take place when we are releasing a software feature/patch/update. Consider the following example:
Code -> Build -> Test -> Package -> Release -> Configure -> Monitor
These are all activities that take place on its own environment, and that need its own people, with its own techniques and procedures and its own metrics.
The 4 types of work
According to the book there 4 types of work:
- Business Projects.- These are business initiatives to reach the company goals.
- Internal IT Projects.- These are mostly infrastructure improvements that may or may not be derived from Business Projects.
- Changes.- Different activities derived from Business and Internal IT projects that can severely affect the production systems.
- Unplanned work / Recovery work.- Production bugs fixing
The idea here is to find where the unplanned work it’s coming from and fix the source ASAP, while accelerating the other types of work that really add value to the business. To do this the book proposes 3 improvement phases called The 3 Ways.
The 3 Ways
The First Way
The first way focus on accelerating the types of work that add value to the business. It does this by streamlining the work flow of the work centers, using techniques such as those from lean manufacturing: identifying value streams and using kanban boards, among others, limit WIP and the theory of constraints: identifying bottle necks and exploit them to the maximum. It relies on mechanisms such as continues build, integration and deployment, automating the creation of environments on demand (using tools such as Vagrant and Docker) and so on.
The Second Way
The second way focus on getting rid of the unplanned work ASAP. It does this by creating faster feedback loops from the work centers down the stream back to the previous control work center until it reach the responsible work center. This allow detection of anomalies and errors earlier int the deployment cycle. It uses techniques such as improvement katas, creating shared goals between departments and creating a production telemetry to make sure that 1) the systems are working fine, 2) the environments are working fine and 3) customer goals are being met.
The Third Way
The third way focus on creating a culture that fosters 1) continual experimentation and 2) repetition and practice. These are requirements to Innovation and Quality which are a must for any business survival these days.
Aligning IT to the business Goals
One of the things that happens a lot to us tech guys, is that we get so focused on technology that we paid less attention to the business it serves. We simply choose to learn technology over domain. This is comprehensible since tech skills are more transferable than domain knowledge for us. But one of the points remarked on the book it’s that first we must understand the goals of the business we are working for. This will give us the criteria to discriminate which projects and changes are important and must receive most of our resources. To me this sounds like the 80/20 rule. Only aligning to the business goals, can IT become a real advantage to the business.
Impressions on the book
I found the book very easy to read. While not as captivating as The Goal, the story line and writing styling weren’t boring. After reading the whole novel, I found some food for thought in the Phoenix Project Resource Guide and later chapters. The DevOps umbrella comprises a lot of tools and practices and Gene Kim and friends have done a very good job organizing those in the three ways. I very much recommending reading the book.
The calculator challenge
It was another normal day on the IT department at a big manufacturing company I was working back then when my boss ask me to see him on his office. It turns out we were starting a new project and needed some extra hands. My boss wanted me to interview potential candidates. It was my first time as a recruiter and a fun experience. I was tasked with finding some experienced OO developers, which can be tricky to say the least. One night it occurred to me that the best way to gauge a developers OO skills are to evaluate his/her design and thinking skills: it’s faster, and you cannot cheat on it (googling it or whatever). That’s how I came up with the calculator challenge.
The problem
Design a program that given a string such as “(1+2)/3*4” returns the correct result. It has to be extensible, meaning that you can add further operations without having to modify the structure of the program to do so (open/closed principle).
I didn’t require the developers to code such a program, just to design it and explain it. It shouldn’t be that hard for a seasoned OO developer to complete the design, but for the guys I interviewed back then, it was puzzling. They could not figure out the SQL to do that. Some other suggested using web services, but no one could ever solve it. My coworker, who was in charge of evaluating the SQL part told me that he wasn’t sure he could do it either. I never told him the answer 😛
So, how would you solve this? Leave your answer in the comments.

OOP: Stop thinking about the data flow!
The main problem with the OO analysis that I’ve seen comes from the inability to leave some thinking patterns that are very routed into our analysis practice. We are animals of habit and while creating them may take at least 3 weeks, getting rid of them it’s usually harder. In this post i would like to suggest some tips to help you change your analysis approach for an OO system.
Forget everything you know
I have this spherical puzzle. Well actually it’s my daughter’s. I brought it to the office and so far only 2 of my companions have been able to resolve it. The skillset required to solve this kind of puzzle it’s very different that the one required to solve a traditional puzzle. Besides considering the shapes that now are 3d, you have an additional restriction on the order the pieces are put together. This alone requires a new thinking process, a new paradigm to try to figure out the solution. If you are a good puzzle solver your old skills are more likely to get in the way than not. It’s the same with this post. I’m just saying, keep an open mind to it.
Messages are not data
Consider the following case: you have to notify whenever a customer status change. This may be whenever a customer is new, or is deleted.
public enum CustomerStatus {New, Removed}
public class CustomerEvent
{
public string Id {get; set;}
public string CustomerStatus Status {get; set;}
...
}
public class CustomerEvents
{
public event EventHandler<CustomerStatus> OnChanged;
}
public void main ()
{
CustomerEvents events = new CustomerEvents();
events.OnChanged += (s,e) =>{
switch(e.CustomerStatus){
case New:
.....
break;
case Removed:
.....
break;
}
};
}
Take 5 minutes before looking the snippet below. Can you spot what’s wrong with this code?
public class CustomerEvent
{
public string Id {get; set;}
...
}
public class CustomerEvents
{
public event EventHandler<CustomerStatus> OnNew;
public event EventHandler<CustomerStatus> OnDeleted;
}
public void main ()
{
CustomerEvents events = new CustomerEvents();
events.OnNew += (s,e) =>{...}
events.OnDeleted += (s,e) =>{...}
}
“So?” – you may say – “what’s the big deal? It’s the same data, just exposed on a different way”. Well, yeah, it’s the same data, but these are 2 different messages. And that’s and important difference. A message is more than just a way to pass data. It’s an explicit request, we may supply some data to help accomplish the request but that’s just it. What’s important it’s the meaning of the message, the thing we are requesting.
If you want to code in an OO paradigm you need to start thinking in that paradigm: start focusing on the message flow, not the data flow.
Messages, messages everywhere
As mentioned before, an OO program can be better understood if we start with the dynamic side of the application. This means, the objects and the messages sent among them. A good starting point is to take a user story and instead of trying to do a flowchart use a sequence diagram. Try it. Even if you already have a flowchart in place try it. Some things to keep on mind while doing it:
- Try to make your messages as explicit as possible.
- Forget about the implementation problems that may arise. Dictate your messages based only on your needs and nothing else.
- Avoid the need to figure out where the data contained in the messages, if any, comes from or what it looks like.
- Stop thinking on functions that receive data and start thinking on messages sent from one object to another.
- Try avoiding getters and setters as much as possible. This will force you to stop thinking of objects as data bags/tables/structs and make you think of them as things that can respond to messages. Instead of asking them for data have them doing whatever you were planning to do with that data in the first place.
- Avoid the use of static functions in any other way than as factory methods.
- Use interfaces for any object that may change a lot, or to encapsulate a particular way of doing things (algorithm).
As time goes on if you keep practicing you’ll find out that the real abstraction is on the messages. Maybe this is what Alan Kay was thinking of when he said that he should have coined the term “message oriented programming” instead of “object oriented programming”. When you have a set of messages, you can just switch the objects and as long as they can respond to them (the messages), your program will continue to work. Your messages are still in place, your objects are the ones that are replaceable.
Another example
Just consider the following c# code:
string yourName = "sam";
var greet = String.Format("hello {0}!", yourName);
The idea in this is calling a function, passing some data to it and expect the result. The static method “Format” uses the class as a module, a container for functions. The OO way of thinking would be to send a Format message to the string object requesting it to do the operation:
string yourName = "sam";
var greet = "hello {0}!".DisplayOnPlaceholders(yourName);
Here the message DisplayOnPlaceholders(yourName) it’s more explicit than just Format. This allows any developer to understand what it does without having to check it’s code to figure it out. You can mimic some of this behavior using extension methods. There’s a huge library on extensionmethod.net/. Check it out.
Closing words
Some of you maybe find this stuff absurd. But if you code in any of the multiparadigm languages out there and want to get better at your OO skills without learning smalltalk, I strongly suggest that you follow this ideas in as much as possible, at least while you’re getting the hang of it (that is until you start thinking of case objects instead of switch statements). Especially if you come from the .net area (like myself). And enjoy coding 😉